

どうも、マサヤです!
この記事は、VBAでのIE操作が初めて or 慣れていない方向けに『Webサイト・システムの情報を取得・設定する方法』をお伝えしていく連載記事となってます!
前回はWebサイトの一ページから情報を取得する方法やHTMLの簡単な見方を紹介しました。

IE操作編 3回目は、Webサイト内の全ページから欲しい情報を一括で取得する方法をお伝えします!
もし、あなたがVBAでのIE操作が初めてなら、IE操作編の1回目から順に読んでくださいね。
では、早速いきましょう!
【動画】Webサイトの全ページから欲しい情報を一括取得
最初に動画で動きを確認しましょう!
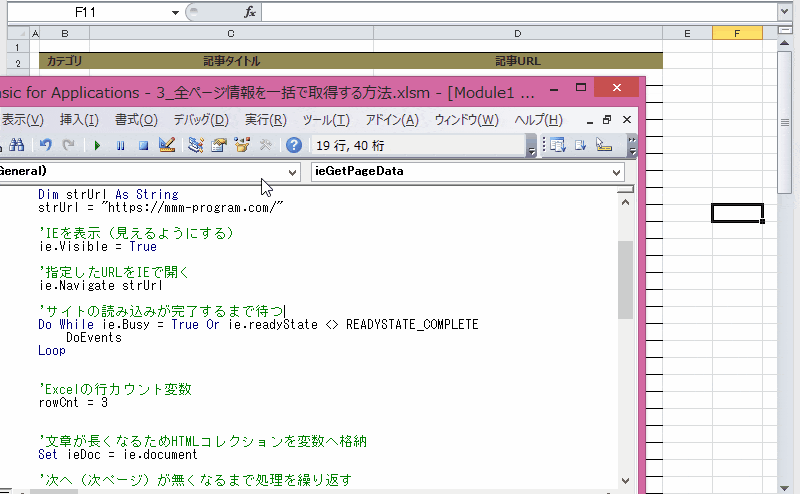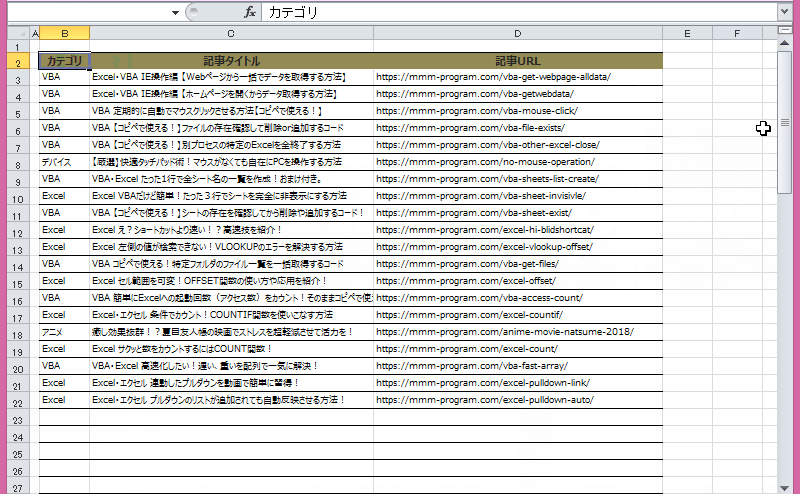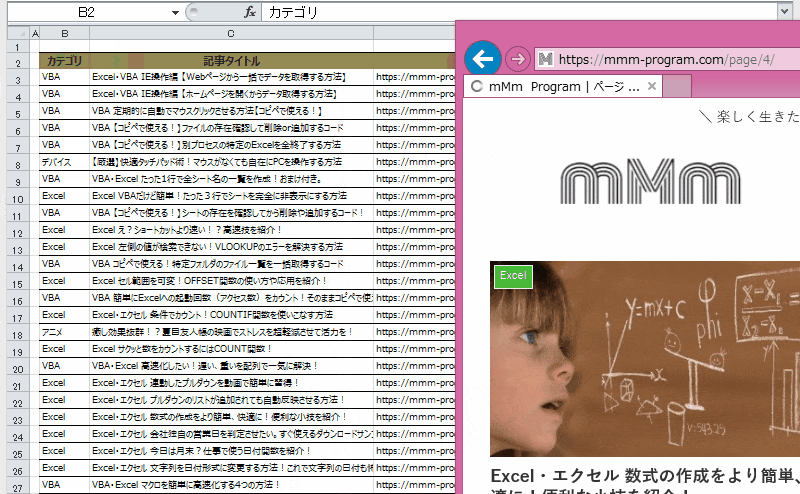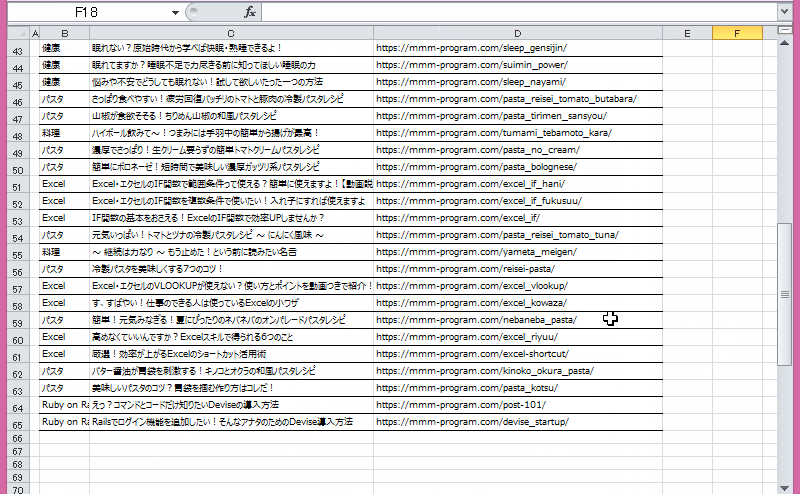
ちょっとワチャワチャ(笑)してますが、一ページずつ移動して全ページのデータを取得しています。
処理としては、Webサイト(当ブログ)の全ページの記事カテゴリ、記事タイトル、記事URLを取得、その結果をExcelへ出力しています。
では、前回のコードと何が違うのか?
コードを見ていきましょう!
Webサイトの全ページからデータを取得するコード
コードはこちら!
Private Declare PtrSafe Sub Sleep Lib "kernel32" (ByVal ms As Long)
Sub ieGetSiteData()
'IEオブジェクトを作成
Dim ie As InternetExplorer
Set ie = CreateObject("InternetExplorer.Application")
'開きたいURLを変数に代入
Dim strUrl As String
strUrl = "https://mmm-program.com/"
'IEを表示(見えるようにする)
ie.Visible = True
'指定したURLをIEで開く
ie.Navigate strUrl
'サイトの読み込みが完了するまで待つ
Do While ie.Busy = True Or ie.readyState <> READYSTATE_COMPLETE
DoEvents
Loop
'Excelの行カウント変数
rowCnt = 3
'文章が長くなるためHTMLコレクションを変数へ格納
Set ieDoc = ie.document
'次へ(次ページ)が無くなるまで処理を繰り返す
Do
'ページ内の記事数を取得
postCnt = ieDoc.getElementById("main").getElementsByClassName("entry-card-wrap").Length
'長いの変数に格納 可読性を高めるため
Set posts = ieDoc.getElementById("main").getElementsByClassName("entry-card-wrap")
'上記で取得した記事数分処理を繰り返す ※カウントは0から始まるため-1する
For i = 0 To postCnt - 1
'記事カテゴリを取得してExcelへ出力
Cells(rowCnt, 2) = posts(i).getElementsByClassName("cat-label")(0).innerText
'記事タイトルを取得してExcelへ出力
Cells(rowCnt, 3) = posts(i).getElementsByClassName("entry-card-title card-title e-card-title")(0).innerText
'記事URLを取得してExcelへ出力
Cells(rowCnt, 4) = posts(i).getAttribute("href")
'Excelへ出力行を次の行へ
rowCnt = rowCnt + 1
Next
'次へのリンクが存在するか確認し、無ければ繰り返しを終了し、存在すれば次へのリンクをクリック。
If ieDoc.getElementsByClassName("pagination-next-link key-btn")(0) = "" Then
'次ページのリンクがないため繰り返しを抜ける(終了)
Exit Do
Else
'次へのリンクをクリックし、次のページへ移動
ieDoc.getElementsByClassName("pagination-next-link key-btn")(0).Click
'待機:クリック後1秒待つ処理。
Sleep 2000
'サイトの読み込みが完了するまで待つ
Do While ie.Busy = True Or ie.readyState <> READYSTATE_COMPLETE
DoEvents
Loop
End If
Loop
'オブジェクトを閉じる
ie.Quit
'メモリからオブジェクトを破棄
Set ie = Nothing
End Sub
前回コードを基本使っていますが、いくつか変更と追加をしています。
それでは、一つずつ見ていきましょう。
次ページのリンク有無で条件分岐させる
今回の一番の肝である、次ページのリンクが有るのか無いのかの条件分岐です。
'次へのリンクが存在するか確認し、無ければ繰り返しを終了し、存在すれば次へのリンクをクリック。
If ieDoc.getElementsByClassName("pagination-next-link key-btn")(0) Is Nothing Then
'・・・省略
Else
'・・・省略
End If
ポイントはNothig使う
この条件分岐でポイントとなるのがNothingを使っている点です。
次ページリンクのクラス名であるpagination-next-link key-btnを、getElementsClassNameで取得しています。
存在すればHTMLコレクションが、存在しない場合はFalse・空白・NullとかではなくNothingが返されます。
そのため、下記のようなIF文を書くとエラーになるので注意しましょう。
If ieDoc.getElementsByClassName("pagination-next-link key-btn")(0) = False
If ieDoc.getElementsByClassName("pagination-next-link key-btn")(0) Is Null
if ieDoc.getElementsByClassName("pagination-next-link key-btn")(0) = ""
条件分岐(IF文)しないとエラーが発生
条件分岐が行わないと、プログラムはどのページでも次ページのリンクをクリックします。
その結果、最後のページでも次ページリンクをクリックし、エラーを発生させることになります。
これを回避するため、現在開いているページに次ページのリンク有無を確認する必要があるわけです。
Clickで次のページへ移動する
前途の条件分岐で次ページのリンクが存在していたら、そのリンクをクリックさせます。
リンクやボタンをクリックする際は、Clickメソッドを使います。
'次へのリンクをクリックし、次のページへ移動
ieDoc.getElementsByClassName("pagination-next-link key-btn")(0).Click
リンクだけでなく、ボタン・ラジオボタン・チェックボックにもClickメソッドは使えます。
左クリック一発のものはClickで対外いけちゃいます)笑
Sleepでプログラム実行を一定時間待機させる
IE操作編においてSleepは結構重要なので、ガッツリ説明してます。
私が以前苦労したので同じ経験をしてほしくない!という思いで書いたら、長くなっちゃいました)笑
Sleepメソッドは、指定した時間(ミリ秒単位で指定)を待機させることできます。
下記コードでは2秒間(2000ミリ秒)待機させています。
'待機:クリック後1秒待つ処理。 Sleep 2000
Sleep使用には、WindowsAPIの宣言が必要
SleepはWindows APIの一つのため、使用するにはコードの一番上に下記を記載する必要があります。
Private Declare PtrSafe Sub Sleep Lib "kernel32" (ByVal ms As Long)
Busyメソッドの前に、Sleep(待機)が必要な理由
Clickメソッド直後にSleepを使って待機させている理由は、リンクをクリックして、ブラウザが次ページ読込開始するまでの時間を待つためです。
「あれ?それは次のコードにあるBusy等で対処するんじゃないの?」
と、思っているかもしれません。
混合しがちなのですが、Busyが受け持つのは読み込みを開始した後になります。
なので、読み込み開始していない状態でBusyコードにプログラムが到達すると、Busy = Falseとなるためプログラムが次の工程へと進んでしまいます。
結果として、エラーや同じページの情報を重複して取得するといった問題が発生します。
これを回避するため、ページ遷移が発生するコードの後にはSleepを差し込む必要があります。
Sleepは動作環境で不要になる場合もある
また、Sleepで指定する秒数に関しても注意が必要です。
PC・ネット環境によりPCの読込速度などが変動するため、2秒ではなく1秒で良い場合やSleepがそもそも不要になる場合もあります。
利用する際は、実際の動作環境で確認しながら調整しましょう。
リンクが存在しない場合はDoを抜ける
条件分岐で次ページのリンクが存在しない場合。
プログラムは最終ページと判断して、下記コードでDoループを抜けます。
'次ページのリンクがないため繰り返しを抜ける(終了) Exit Do
ここはシンプルですね。
Do~Loop(32~66行目)で囲むことで、ページ毎の処理を繰り返し実行しています。
そして、ページ処理の最後に次ページリンク有無を確認、存在しなければ最終ページと判断しDoを抜けています。
まとめ
IE操作編の3回目 Webサイトの全ページからデータを一括取得する方法をお伝えしました。
今回のコードを流れをまとめると下記になります。
今回でWebサイトから欲しい情報を漏れなく取得できるようになったかと思います。
前途のコードをカスタマイズすれば、アルバイトサイトの情報取得して、全国・エリア別など様々な角度から平均時給や募集件数などを計算したり、ショッピングサイトから商品名と価格等を取得して価格相場を調べたりと、アイディア次第で色々できますよ。
かなり実用的になってきましたね。
次回(IE操作編3回目)は、より実用的にするためWebサイトへのデータ設定をお伝えします!
これにより、検索バーに検索ワードを入力・検索、結果の情報を取得したり、Webシステムへのデータへ入力し登録、ログイン画面へのログイン等々、より様々なことができるようになります。

コメント