

どうも、マサヤです!
この記事は、VBAでのIE操作が初めて or 慣れていない方向けに『Webサイト・システムの情報を取得・設定する方法』をお伝えしていく連載記事となってます!
前回(1回目)はIE起動~データを一つ取得するまで行いました。

ただ、実際のところ一つだけデータを取得するケースはあまり無いですよね。
例えば記事タイトルだったら、開いたページの記事タイトルを全部取得することが多いでしょう。
そこで、IE操作編の2回目の今回は、開いたWebページのデータを一括で取得する方法をお伝えします!
では、今回も張り切っていきましょう!
【動画】Webサイトのページを一括取得
まずは、実際の動きを動画で確認して見ましょう!
動きとしては、Webサイト(当ブログ)のTOPページ内の記事タイトル、カテゴリ、記事のURLを取得。
その取得結果をExcelへ出力しています。
さて次はコードを見ていきましょう!
VBA Webページ内のデータを一括で取得するコード
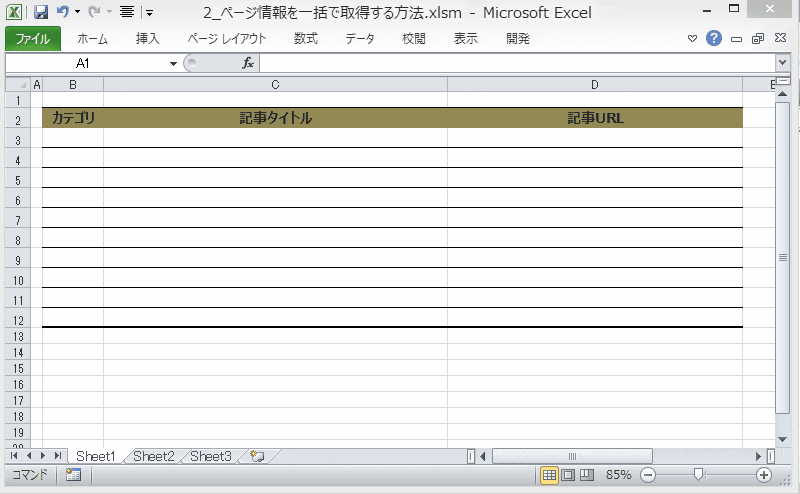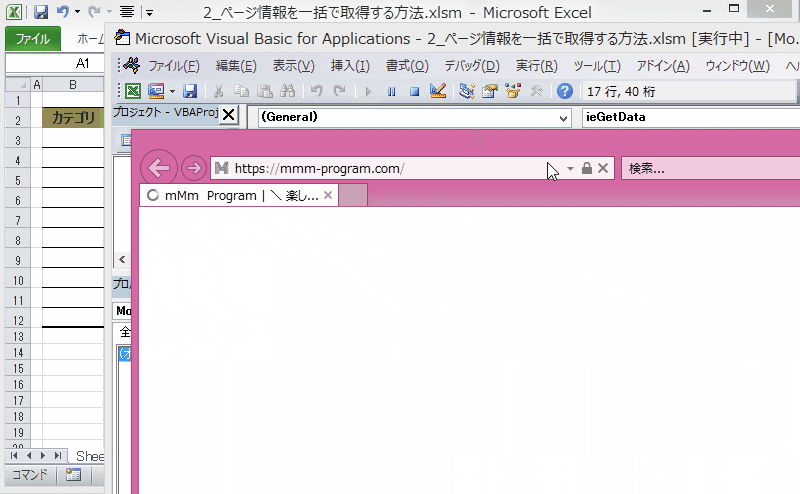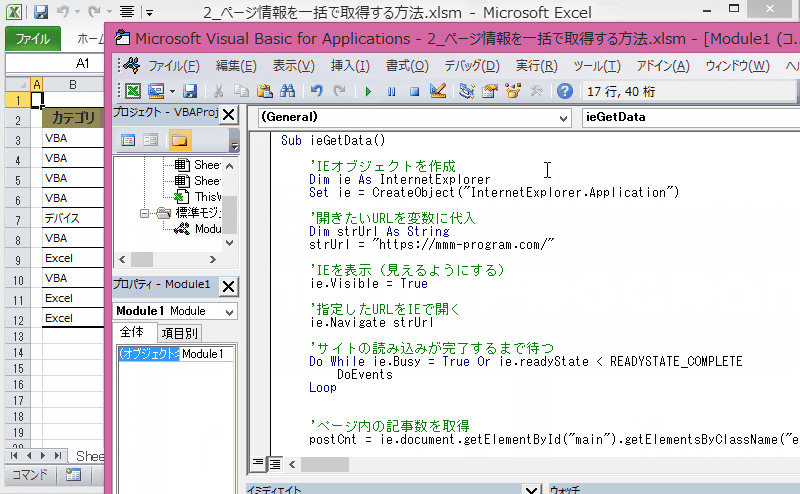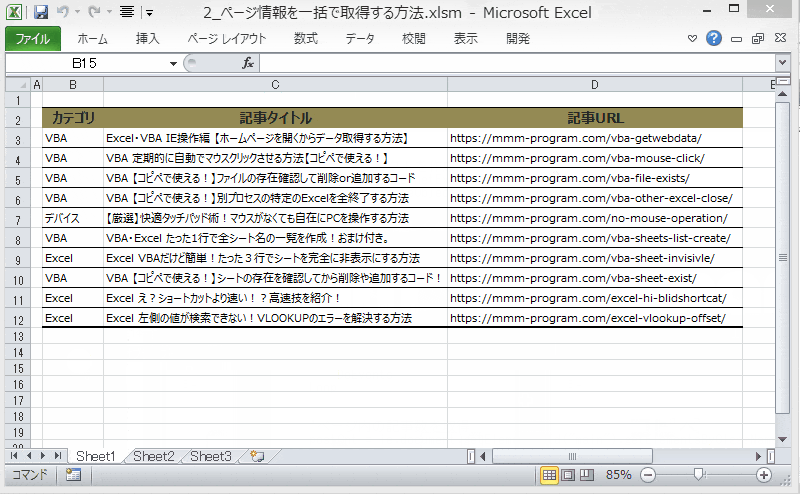
実際のコードはこちら!
Sub ieGetPageData()
'IEオブジェクトを作成
Dim ie As InternetExplorer
Set ie = CreateObject("InternetExplorer.Application")
'開きたいURLを変数に代入
Dim strUrl As String
strUrl = "https://mmm-program.com/"
'IEを表示(見えるようにする)
ie.Visible = True
'指定したURLをIEで開く
ie.Navigate strUrl
'サイトの読み込みが完了するまで待つ
Do While ie.Busy = True Or ie.readyState < READYSTATE_COMPLETE
DoEvents
Loop
'ページ内の記事数を取得
postCnt = ie.document.getElementById("main").getElementsByClassName("entry-card-wrap").Length
'長いの変数に格納 可読性を高めるため
Set posts = ie.document.getElementById("main").getElementsByClassName("entry-card-wrap")
'Excelの行カウント変数
rowCnt = 3
'上記で取得した記事数分処理を繰り返す ※カウントは0から始まるため-1する
For i = 0 To postCnt - 1
'記事カテゴリを取得してExcelへ出力
Cells(rowCnt, 2) = posts(i).getElementsByClassName("cat-label")(0).innerText
'記事タイトルを取得してExcelへ出力
Cells(rowCnt, 3) = posts(i).getElementsByClassName("entry-card-title card-title e-card-title")(0).innerText
'記事URLを取得してExcelへ出力
Cells(rowCnt, 4) = posts(i).getAttribute("href")
'Excelへ出力行を次の行へ
rowCnt = rowCnt + 1
Next
'オブジェクトを閉じる
ie.Quit
'メモリからオブジェクトを破棄
Set ie = Nothing
End Sub
23行目以降が前回との違いになります。
23行目以降のコードを一つずつ見ていきましょう!
※23行目以前の説明は前回記事をご覧ください!
1. Lengthでページ内の要素数を取得
一括取得するためには、まず欲しい情報がページ内にいくつあるかを取得します。
今回取得するのは記事タイトル、記事カテゴリ、詳細URLを取得するので、記事数を取得すればOKですね。
下記コードで記事数を取得し、変数postCntへ格納しています。
postCnt = ie.document.getElementById(“main”).getElementsByClassName(“entry-card-wrap”).Length
長い一文ですが、ドットで区切って一つずつ見ていくと解りやすくなります。
このメソッドをドット区切って記載する手法をメソッドチェーンといい、左から右へ取得したメソッド結果を渡すことができます。
一行で記載でき、処理を明確するメリットがありますが、逆に一文が長くなりすぎると可読性が悪くなります。
メソッドチェーンは後半のコードでも使ってますが考え方は同じです。
2. getElement関連メソッドで記事要素を変数に格納
メソッドで記事要素を変数postsに格納してます。
変数に代入せずともコードは書けますが、かなり長い一文となり可読性が悪くなります。
なにより、コードを見直した際に理解し易いように、ページ内の全ての記事要素を変数に格納しています。
当ブログの1ページに掲載できる記事数は10記事です。
つまり、上記コードでは10記事分の情報を変数に格納したことになります。
3. Forで記事要素を一つずつ処理
前項で変数posts に全記事分の要素を取得しました。
後は、For文を使って1~10記事までを一つずつ参照・処理していきます。
Forの繰り返し回数の考え方
※For文を理解しているあなたは飛ばしてください。
PostCnt-1となっているのは、メソッドの要素番号は0から始まるためマイナス1となります。
PostCntには10(10記事)が格納されているので、処理を10回繰り返したいことになります。
postsの要素番号は0から始まるので、0,1,2,3,4,5,6,7,8,9と10回繰り返すわけです。
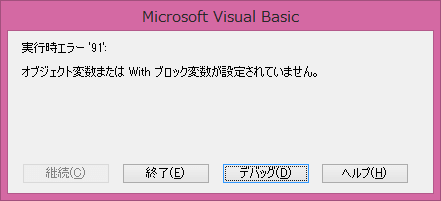
ここで、マイナス1せずに処理を行うと、0, 1,2,3,4,5,6,7,8,9,10と、11回処理を繰り返すことになり、最後の11回目の処理で記事が10個までしかないのに、11個目を取得しようと処理が動くためエラーとなります。
要素番号を間違えた時のエラー画面
要素番号(添え字ともいいます)を間違えると下記のようなエラーが表示されます。
For Eachでも処理できる
もうお詳しい方であればお気づきだと思いますが、For Eachでも利用できます。
要素番号などを気にかけず記載ができるのがいいですよね。
For文のコード箇所をFor Eachに変更したものは下記となります。
色々なプログラムを触っているとこちらのほうが馴染みがあるかもしれませんね。
あなたの好きな方を使ってください。
For Each Post In posts
'記事カテゴリを取得してExcelへ出力
Cells(rowCnt, 2) = Post.getElementsByClassName("cat-label")(0).innerText
'記事タイトルを取得してExcelへ出力
Cells(rowCnt, 3) = Post.getElementsByClassName("entry-card-title card-title e-card-title")(0).innerText
'記事URLを取得してExcelへ出力
Cells(rowCnt, 4) = Post.getAttribute("href")
'Excelへ出力行を次の行へ
rowCnt = rowCnt + 1
Next
4. innerTextで記事カテゴリ・タイトルを取得
For文内のコードです。
記事カテゴリと記事タイトルを取得して、Excelを出力しています。
Cells(rowCnt, 2) = posts(i).getElementsByClassName(“cat-label”)(0).innerText‘記事タイトルを取得してExcelへ出力
Cells(rowCnt, 3) = posts(i).getElementsByClassName(“entry-card-title card-title e-card-title”)(0).innerText
これもドットで区切ってみましょう。
ちなみにposts(i)には、ie.document.getElementById(“main”).getElementsByClassName(“entry-card-wrap”)(0)が格納されています。
これを踏まえて読み解く必要があります。
例えば、postsをコードに戻してiを0とした場合の一文は下記になります。
読み解くと、全記事要素内にある、0番目(1記事目)の記事要素内のクラス名:cat-labelが付与されている0番目の要素内にあるテキスト情報を取得する。
というコードの意味となり、記事タイトル取得も同じように読み解けます。
5. getAttribute(“href”)で記事URLを取得
初めて見るメソッドが出てきましたね。
Cells(rowCnt, 4) = posts(i).getAttribute(“href”)
getAttributeは指定した属性の値を抽出できます。
今回していしている属性は、hrefなので記事URLを取得しています。
6. QuitでIEオブジェクトを閉じる
ie.Quit
具体的にはIEが終了します。IEがPC画面上に表示されていれば閉じられます。
これをしないと、IEが起動したままになります。
Visibleで見えないようにしていても、バックグラウンドでは動いてますので注意が必要です。
7. Nothingでオブジェクトを破棄・解放
最後になります。
これを行うことでIEオブジェクトを破棄し、メモリを解放します。
Set ie = Nothing
といっても、プログラムが終了した段階で解放されるため、実際はこのコードは必要ありません。
記載している理由は「ここでオブジェクトを破棄しますよ」と明示するために書いてます。
よく使うメソッド
さて、ここではIE操作(オブジェクト)でよく使う3つメソッドを紹介します。
- getElementsByClassName(name)
- getElementsByTagName(name)
- getElementById(name)
getElementsByClassName(name)
私が仕事で一番良く使うメソッドで、今回のコードでも使ってますね。
⇒ nameで指定したクラス名の子要素含めたHTMLコレクションを取得。
ポイントとしては、同じくクラス名が複数ある場合に対応するために、配列に似たようなオブジェクトを取得する点です。
「なるほど・・・わからん!」
と、昔の私はなりましたので、簡単なHTML(サイト)で説明します。
<html>
<head></head>
<body>
<h1>僕の好きな食べ物</h1>
<div class="blog-card" id="food">
<h2>焼肉</h2>
<p>美味しいよね!</p>
</div>
<div class="blog-card">
<h2>お寿司</h2>
<p>これも美味い!</p>
</div>
<div class="blog-card">
<h2>ケーキ</h2>
<p>甘~~~い!</p>
</div>
</body>
</html>
このHTMLに対して、Set Foods = getElementsByClassName(“blog-card”)を実行します。
すると、変数Foodsには下記のデータが格納されます。
配列のようなデータが格納されているのが解りますね。
そして、指定したクラスの要素である<div>だけでなく、子要素である<h2><p>も一緒に格納されます。
では、なぜ配列ようなデータ形式になるのか?理由はHTML構造に関わってきます。
HTMLでは同じクラス名がページ内で何度でも使えるようになっており、同じクラス名が1個のページもあれば、10個のページもあるわけです。
それに対応するために、getElementsClassNameは前途のとおり配列のようなデータ構造をとっており、同じクラス名が何個でも格納できるようになってます。
あと、配列ということは要素数を確認できるLengthプロパティも用意されています。
紹介したコードでも使っており、繰り返し処理するときに使えますよ。
getElementsByTagName(name)
HTMLのテーブルや文章内の強調文字だけを取得したい時などに使うメソッドです。
⇒ nameで指定したタグ名の子要素含めたHTMLコレクションを取得。
上記のHTMLを例に、Set Foods = getElementsByTagName(“h2”)とした場合、変数Foodsは以下のようになります。
クラスがタグに代わっただけ、他の部分はgetElementsTagNameと同じですね。
getElementById(name)
サイトによって、要素に固有のidが付与されている場合に使ったりします。
⇒ nameで指定したidの子要素含めたHTMLコレクションを取得。
ポイントとしては、getElementsClassNameやgetElementsTagNameと違い複数の要素を持ちません。
HTMLのページ内で同じidは利用できないためです。
逆にいうと、ピンポイントでデータに参照できる点は長所ですね。
上記のHTMLを例に、Set Food = getElementById(“food”)とした場合、変数foodは以下のようになります。
前途した通り、複数要素は持たず指定したidの要素のみを取得しています。
取得したいデータ要素をHTMLから簡単に探す方法
よく使うメソッドを紹介しましたが、どうやって取得したいid・class・Tagの名前をWebから探すのでしょうか。
そこで、HTML知識がなくても簡単に探す方法を、当ブログを例にお伝えします!
今回は当ブログの記事タイトルを取得する時に必要な名前を探します。
1. Webサイトを開いて、F12を押す。
サイトを開いた状態でF12を押すと、デベロッパーツールが起動します。

2. 矢印アイコンで取得したいデータをクリックし名前を確認。
次はデベロッパーツールにある、矢印アイコンをクリックして、記事タイトル部分をクリックします。

そうすると、選択された箇所のHTMLが薄く青色になって表示されるので、使えそうな名前を確認します。
今回のコードではclass=”entry-card-title card-title e-card-title”をgetElementsClassNameで使用し記事タイトルを取得しました。
まとめ
IE操作編の2回目 Webページの情報を一括取得する方法をお伝えしました。
今回のコードをまとめると下記になります。
HTMLから欲しいデータの探す方法なども理解でき、Webページ内の情報は取得できるようになったと思います。
でも、2ページ、3ページと何ページもあった場合は今回のコードでは対応できません。
そこで!次回のIE操作編 3回目は、
次ページをクリックし、Webサイト全てからデータを取得する方法を紹介します!お楽しみに!

コメント
初めまして。ゆうと申します。
仕事でWebサイトのデータ取得をしないといけなくて、色々調べてたらこのサイトにたどり着きました。
とてもわかりやすく勉強になりました。
下記サイトの情報も取得できるのでしょうか?
ぜひアドバイスをお願いします。
https://itp.ne.jp/keyword/?keyword=%E8%A3%BD%E9%BA%BA&areaword=%E5%A4%A7%E9%98%AA%E5%BA%9C&sort=01&sbmap=false
現在スクレイピングの勉強をしている者で質問があります。
上のコードではoption explicitで宣言されていないと思うのですが、仮にdim で変数を定義するとしたら型は何になるのでしょうか。
特に知りたいのは postsの型です。
dim posts as 「???」
よろしくお願いいたします。
ななしさん
記事を見ていただきありがとうございます!
型を宣言するとした場合はHTMLDocumentになります。
なので、dim posts As HTMLDocument ですね。
返信ありがとうございます!
いろいろスクレイピングに挑戦して自分が欲しいデータを抜き出せるようになりました!
ありがとうございます!
よかったです!